Since conventional AI technologies were not suitable for our purposes, we decided to start from scratch and develop our own technology. It was important for us to overcome the following limitations:
- Neural nets always need highly structured input data: These are generally prepared by a very homogeneous group and so it often happens that biases arise already before the training.
- The interaction with AI is reserved for only a few: Mostly software developers and data scientists. This also leads to biases that occur already in the development phase and continue throughout the entire training process (training of neural networks) until the output of the AI.
- All AI systems are based on a probabilistic inductive system (stimulus-response scheme). This means that independent reasoning (thinking and creativity) is not possible with it.
- Lack of transparency: Neural networks are still a black box.
- Compatibility with quantum computers: As of yet, there are no future-proof AI algorithms that run on quantum computers
- Existing AI systems require high computing power, hence consume huge amounts of electricity
These were the reasons why we have created a completely new AI-technology which is the first thinking General Artificial Intelligence in the world. This has paid off, because we have created a system that has the following advantages:
- Our solution can work with any kind of input data. These do not need to be specifically prepared by humans.
- Interaction with our system is in natural language (any possible language) including the training as well as the verification of the results. Thus, anyone who can read and write can work with our system.
- Our system is based on empirical deductivism. Thus, thinking[1] is also possible.
- In our neural networks there is transparency inside and outside the neural networks.[2]
- We are the first company in the world to develop quantum neural networks[3] running on quantum computers (IBM).
- Our solution requires 80% less computing power, hence consuming less electricity than standard AI-solutions.[4]
Xephor Quantum Neural Networks:
In the last years there has been tremendous progress in the field of Artificial Intelligence, in particular regarding Artificial Neuronal Networks (ANNs) which are structures that can be thought of as consisting of stacked layers of computational nodes called artificial neurons. Each layer receives input from the previous layer and sends data to the following layer in the following way: Every artificial neuron of a layer receives input signals from a plurality of artificial neurons from the preceding layer and uses these input signals to compute a single output signal which is then sent together with the output signals of the other artificial neurons of this layer to the artificial neurons of the next layer. It is important to know that signals coming from different artificial neurons of the preceding layers are given different weights when calculating the output signal.
An ANN must be trained using training data to work properly. The training data is used, for each artificial neuron, to find the “correct” weights that should be applied to the input signals such that the ANN gives correct results.
Conventional ANNs need:
- a lot of highly structured training data needed
- can have the problem of becoming “unstable” such that training must be restarted
- need a lot of computational power
Result: The entire effort is very tedious: data must be available in a certain quantity and must be prepared in a complex way so that it can be processed at all. This also means that there is no flexibility to quickly run tests with other data. In addition, the entire process is a real energy guzzler: enormous hardware resources have to be used to keep the process running.
It’s much simpler and less complicated with Quantum Neuronal Networks (QNNs):
QNNs use one of Quantum Mechanics most striking features, “Entanglement”. In a sense, two quantum systems are called “entangled” when it is possible to change one quantum system by influencing the other quantum system, no matter how far the two quantum systems are away from each other.
In QNNs the weights of the artificial neurons are not “corrected” independently from each other but in such a way that they show features best called “entangled”, i.e. a correction of one of the entangled weights changes all of the other entangled ways.
Result: QNNs have a variety of advantages compared to conventional ANNs:
- they need far less training data (about 10 % of the amount needed for ANNs)
- they run stable, therefore there is no need to restart training
- it is possible to parallelly correct a lot of weights which reduces the amount of computation power by 80%
And the highlight: QNNs can also be adapted to run on quantum computers!
For those who want to know exactly how QNNs are working:
https://data.epo.org/publication-server/document?iDocId=6688580&iFormat=2
Our contribution to sustainability:
Because we built a new technology from scratch, we were able to make sure we built the most sustainable AGI possible from the start. We have achieved this through the following three aspects:
- Choosing the right programming language: C and C++. Compared to Python, this is 72x faster and uses 76x less energy[1]
- Massive Parallelization: Processes are broken down into different subtasks that run synchronously (a task is broken down into roughly equal parts) on the one hand and asynchronously (tasks are executed asynchronously in parallel) on the other. In addition, scalability quickly deteriorates as the number of CPUs increases.[2]
- Orientation to the human brain (neuromorphic AI/AGI):
Classical AI computational intensity: 1 hour of OpenAI’s GPT3 = 2,000,000 km by car.
AGI computational intensity: 25 KW = 0.002% of GPT3
Why? In classical AI, neural networks are built bigger and bigger. Then all the input is fed in and transported further and further. This results in exponential growth and power consumption increases to infinity. We work with many small neuronal networks, which are modeled on parts of the human brain in terms of functionality (= humanoid structure and access). Input data is broken down into small building blocks and selectively sent to individual neural networks that are needed. This means flat linear growth with minimal energy requirements.
Machine Thinking
Our biggest innovation is what we call machine thinking. For the first time, it is possible for an AI to generate independent ideas and to react to untrained content. To accomplish this, we took the human brain as role model because it has an astonishing ability to deal with complex information in real-time.
For many years, research in Artificial Intelligence has tried to mimic that ability with results that begin to transform our everyday life. It is now possible for an Artificial Neuronal Network (ANN) to recognize objects and persons in a live video stream paving the way to autonomous driving. For this to be possible, the different parameters of the ANN must be finetuned which is done by supervised training, i.e., a supervisor provides the ANN with training data and checks whether the ANN provides correct results.
To the researcher’s astonishment, tasks that seem very easy to a person are quite difficult for an ANN. For example, imagine a logistic distribution center where packages of different shape and size must be reliably recognized and sorted, even if they have been damaged in transport and do no longer have nice geometric shapes. No problem for a person but next to impossible for an ANN without extensive supervised training.
Xephor Solutions has succeeded in creating a General Artificial Intelligence system which can successfully perform any intellectual task which a human being can do after minimal supervised training so that it can be viewed as an Artificial Brain.
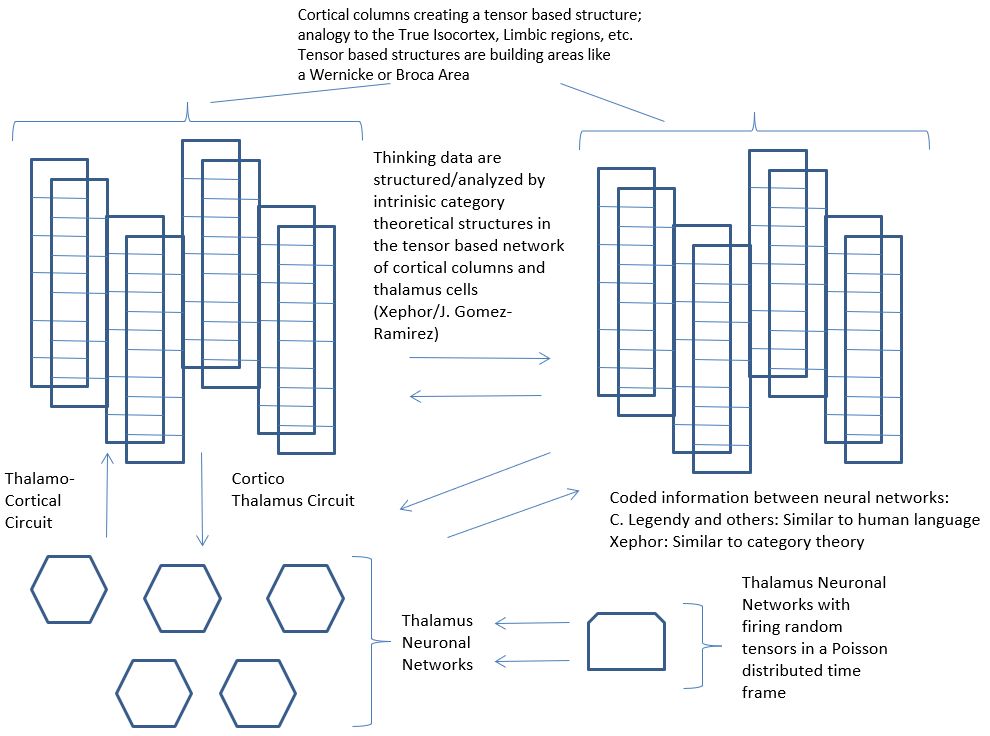
Xephor Solutions’ Artificial Brain comprises thousands of ANN organized in neuronal columns. Each neuronal column is entrusted with a specific task. When the Artificial Brain is provided with a data stream, the neuronal columns continuously check whether there is something in the data stream which they are supposed to work on. To facilitate these tasks a separate computational process divides the data stream into small data chunks which are tagged so that the neuronal columns can easily recognize those data chunks which they are supposed to work on.
Astonishingly, by organizing the neuronal columns into larger work units using concepts from the mathematical field of category theory, XephorSolutions’ Artificial Brain is able to learn in an unsupervised way. Coming back to the logistic distribution center given as an example above, once a work unit of neuronal columns has been trained to recognize a box-shaped package irrespective of size, color and transportation damages, other neuronal columns which represent the categorical concept of a “functor”[1] send these results to a different work unit which is supposed to recognize packages of irregular shape so that this work unit does not need separate supervised training.
This leads to a thinking circuit[2]:
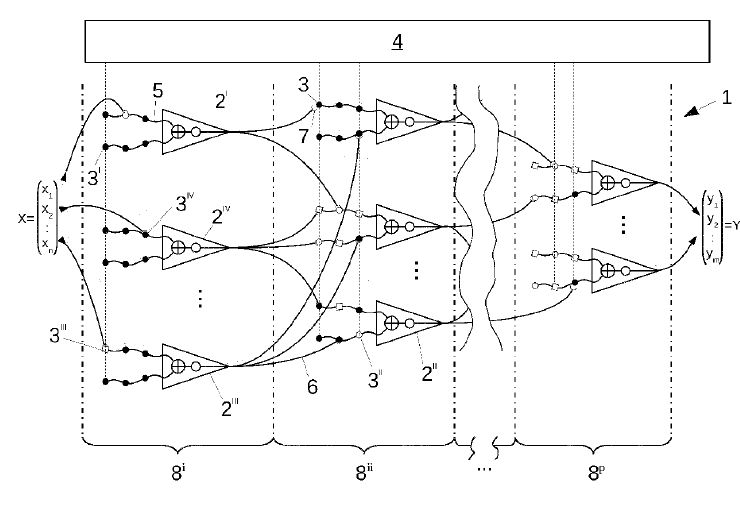
- Special neurons in the thalamo-neural networks generate structured random data. These random data are sent to the surrounding neural networks.
- The neural networks receive them and start sending them to the different cortical columns according to their structure. The data are sent from the thalamo neural networks to the corresponding cortical columns as if through a gateway/hub and further classified. This happens mostly in a circuit between the thalamo neural networks and the cortical columns. After the data or parts of the data have been classified as meaningful, they are sent back to the thalamo neural networks. These now try to locate the cortical columns available for these data and send them there.
- The data are appropriately structured by the category-theoretically modeled networks of neural networks, e.g., into data that the system can understand and data that makes sense but that the system do not know if it is correct in context. In case of uncertainty, the system queries the environment (trainer, compiler, sensor, etc.).
Once this classification is done, output data are given in the desired form (e.g., chart, graph, number series, natural language). The machine thinking model affects the nature of learning: As new content is learned the AI uses reasoning to try to make and understand connections from the information in the sentence. In the process, this content is compared to previously learned data. This is especially important for learning from context, as it allows the system to constantly check what knowledge is already available on a given topic and what conclusions can be drawn from it. This means that new and existing content is
placed in meaningful contexts. Information should have a similar structure in order to be defined as meaningful. This allows the AI to interpret new content.
Which advantages does this circuit of thinking provide?
- No cleaning or structuring of data is needed before the AI-system (“artificial brain”) is trained
- 20 times fewer input data needed (patented)
- 80% less computing power required. Therefore, also substantial energy savings (patented)
- 99.9% less programming as it is a general-purpose system
- Evolved problem solving: Ability to provide new ideas and react to new and unforeseen situations (patented)
- 1,000,000,000 times faster on Quantum computers
More technical details can be found here:
https://at.espacenet.com/publicationDetails/originalDocument?CC=EP&NR=3961508A1&KC=A1&FT=D&ND=3&date=20220302&DB=EPODOC&locale=de_AT#
[1] Machine thinking can be seen as an extremely advanced and biologically oriented variant of GNN (Graph Neural Nets)
[2] Analog to the thalamic dynamic core theory
[1] https://sites.google.com/view/energy-efficiency-languages/
[2] Patent: https://pdfstore.patentorder.com/pdf/us/795/us2019243795.pdf
[1] Machine thinking, not human thinking. This means that the system is able to generate new ideas and react to not trained and unforeseen situation. Pending patents: Category Theory (Machine Thinking), EP20193672, Random Number Generator, EP21179252
[2] For more information please see : Outline of a trustworthy AI, CSR and Artificial Intelligence, Reinhard Altenburger,Springer Verlag, 2021
[3] Pending patent: Parallel Stochastic Quantum Neuronal Networks, EP21173761.4, US17/319708
[4] Patent: US 2019243795 A1
You want to get to know more about our General Artificial Intelligence – just connect with us here!
Contact Data
Media Resources
Download Xephor Logo (PDF)
Download Xephor Logo (PNG)
{kind=link}
Press Contact
Dr. Isabell Kunst
office@xephor-solutions.com